vLLM使用记录
最近水杉计算教育公共课改革,老师想在水杉内做一个为学生答疑的机器人,后端大模型的部署工作由我负责。之前做过一些相关的测评工作,最终选择后端提供服务的模型为deepseek-coder-33b-instruct,部署在单张A800上。功能上线以后需要提供在线服务,一个很自然会想到的问题就是如何应对在线情况下的高并发需求。如果只是简单地部署完让它排队处理请求再输出,以平均处理时长10s计算,在线使用人数只要达到两位数后续的等待时间就让人难以接受了,这样的在线答疑机器人显然是不具备实用性的。在显卡资源有限的情况下,使用多卡部署模型再分摊请求流量这种做法也不现实,那么应该怎么办呢?我们很容易就会想到引入消息队列中间件进行解耦+异步处理这一方法。消息队列中间件可以购买阿里云提供的服务,而异步处理通过vLLM内置的AsyncEngine与python的AsyncIO结合就能够做到这一点,另外,作为一个大模型推理加速框架,vLLM的PagedAttention和ContinuousBatching机制也为单卡部署模型提供在线服务的实现成为可能。
vLLM简介
vLLM是一个用于大模型并行推理加速的框架,由加州大学伯克利分校于2023年6月在论文Efficient Memory Management for Large Language Model Serving with PagedAttention中提出,吞吐量比HuggingFace Transformers高出了24倍。
PagedAttention
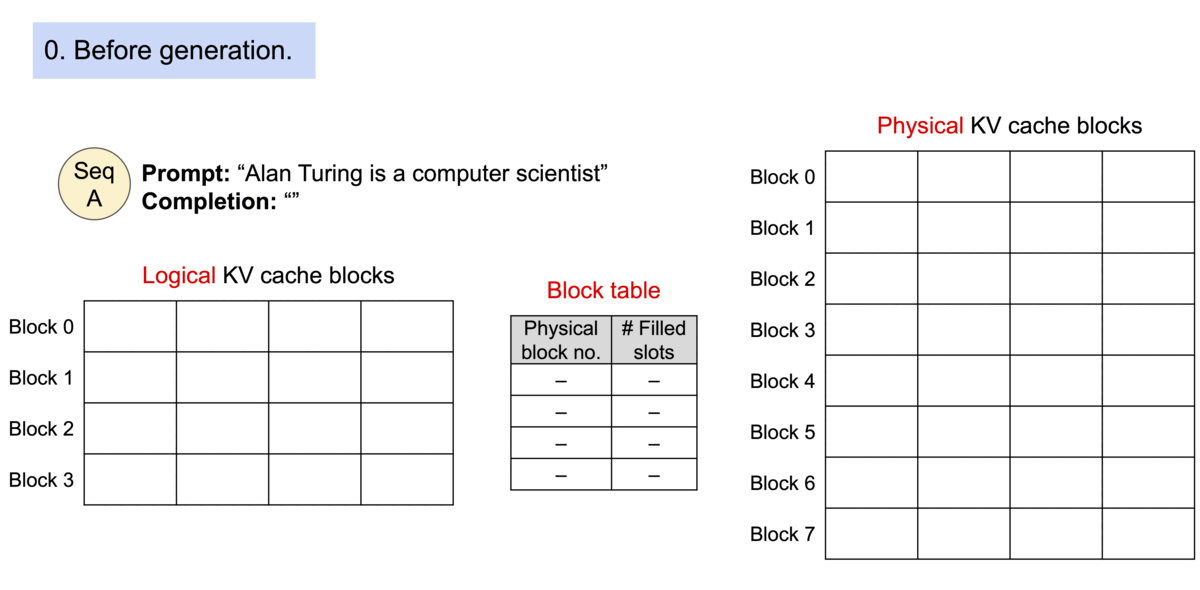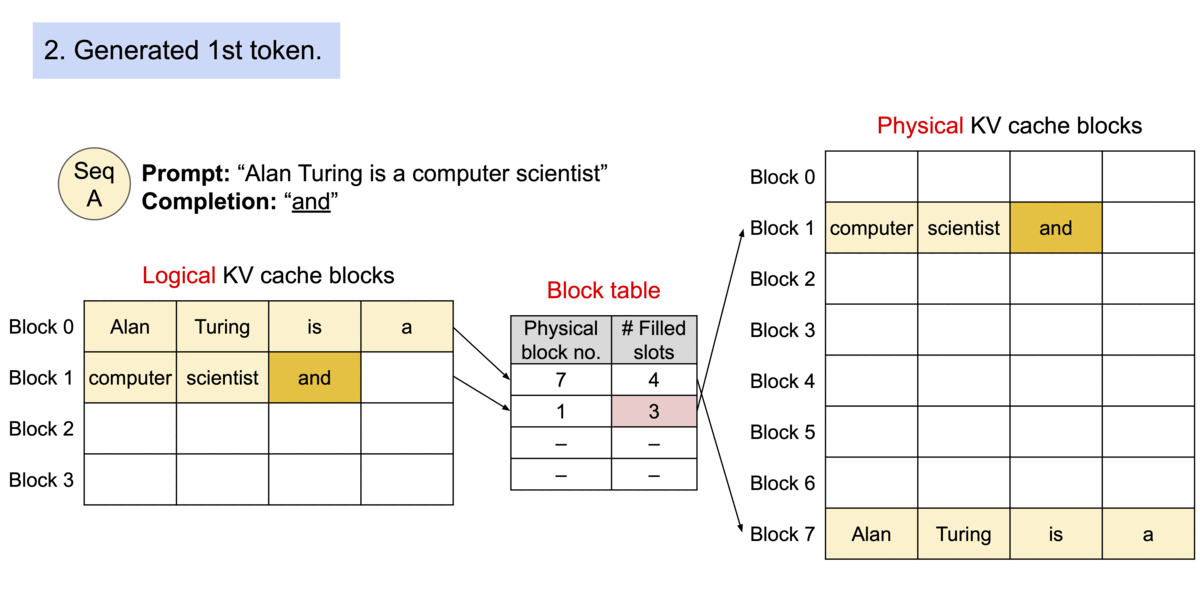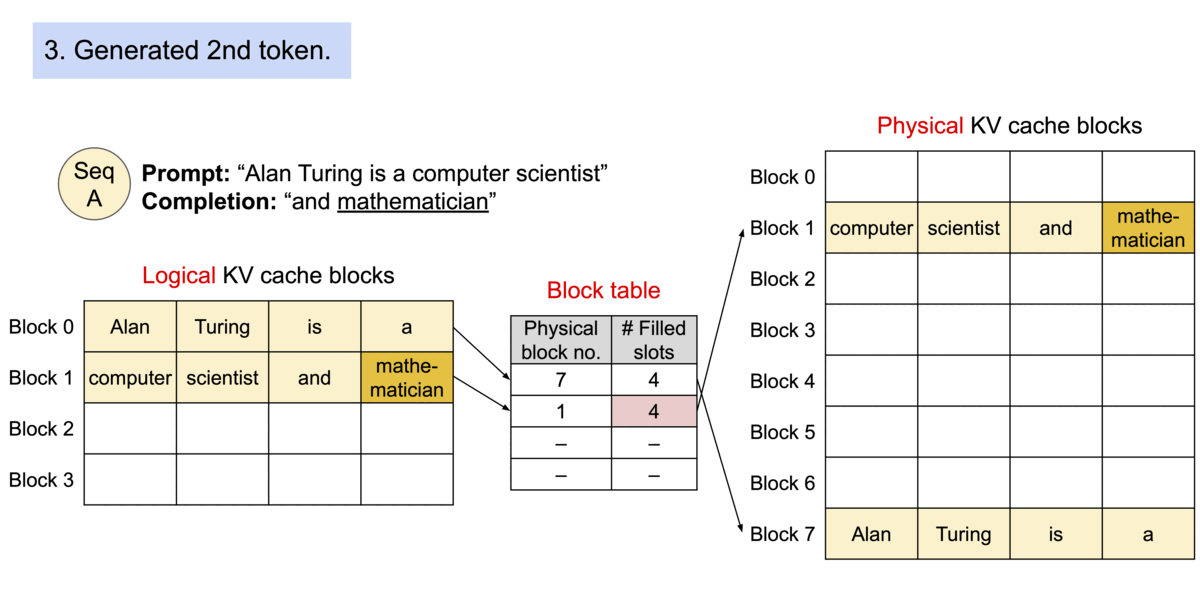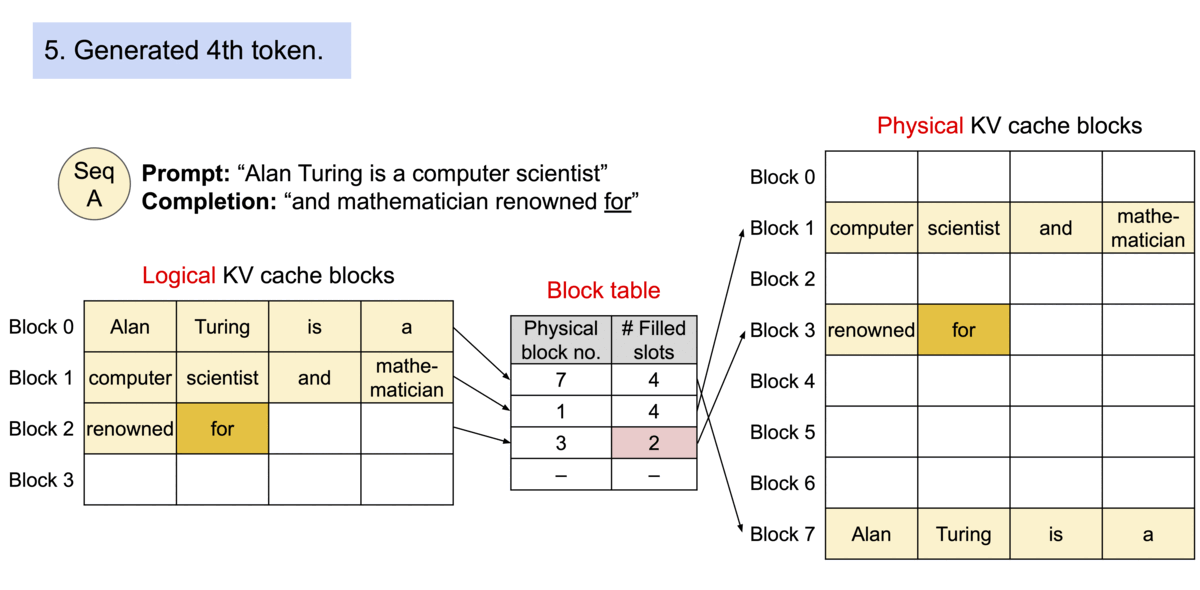
vLLM的核心之一是PagedAttention算法。这是一种受操作系统中虚拟内存和分页的经典思想启发的注意力算法。与传统的注意力算法不同,PagedAttention 允许在不连续的内存空间中存储连续的key和value。具体来说,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量token的key和value。在注意力计算过程中,PagedAttention 内核有效地识别并获取这些块。因为块在内存中不需要是连续的,所以我们可以像在操作系统的虚拟内存中一样以更灵活的方式管理key和value:可以将块视为页面,将token视为字节,将序列视为进程。序列的连续逻辑块通过块表映射到非连续物理块。当新token生成时,物理块会按需分配。